
Enabling the Chiplet Era
Fabric and Cache Architecture

“It may prove to be more economical to build large systems out of smaller functions, which are separately packaged and interconnected. The availability of large functions, combined with functional design and construction, should allow the manufacturer of large systems to design and construct a considerable variety of equipment both rapidly and economically.”
Gordon Moore, Cramming More Components onto Integrated Circuits, April 1965
In his prescient 1965 paper, Gordon Moore alluded to an eventual “Day of Reckoning” when he foresaw an economic imperative to break out large monolithic “functions” into smaller, interconnected “functions”. Gordon Moore was likely envisioning what eventually became Multi-Package Modules (MPMs) that are now common in everyday consumer appliances like the iPhone which combines a memory chip unit (with Dynamic Random Access Memory or DRAM) and a logic chip unit (an Application Processor Unit or APU), separately packaged and interconnected into a single larger unit. Advances in wafer-level packaging technology over the last decade have now made it possible to also envision Moore’s 1965 prediction at a single package level, where large monolithic functions (chips) can be broken into smaller functions (chiplets), connected with extremely high bandwidths to create a much larger, virtually monolithic chip within a single package.
The thriving semiconductor ecosystem that evolved over five decades to support the efficient design and manufacturing of monolithic, standalone Systems on a Chip (SoC) is evolving yet again to enable the efficient design, manufacturing and assembly of discrete chiplets into integrated Systems in a Package (SiP). This transformation from SoC to SiP has been underway for a few years already but is now reaching an inflection point driven by a combination of technological and economic imperatives.
This paper discusses the key pre-requisites for chiplet based designs and highlights the foundational enablers that will democratize the chiplet design ecosystem and drive this transformation at-scale.
From SoC to SiP
Over the last few decades, exponential increase in transistor counts on a chip led to a commensurate increase in chip design complexity. This complexity was effectively managed by periodic innovations that enabled progressively higher levels of abstraction in both circuit design (e.g. using Electronic Design Automation or EDA tools) as well as in chip architecture (e.g. using fully validated and verified intellectual property or IP blocks) to design ever larger monolithic chips. The upcoming transition from designing large monolithic chips to designing smaller, fully validated discrete chiplets can be seen as the logical next step up the design and architecture abstraction stack.
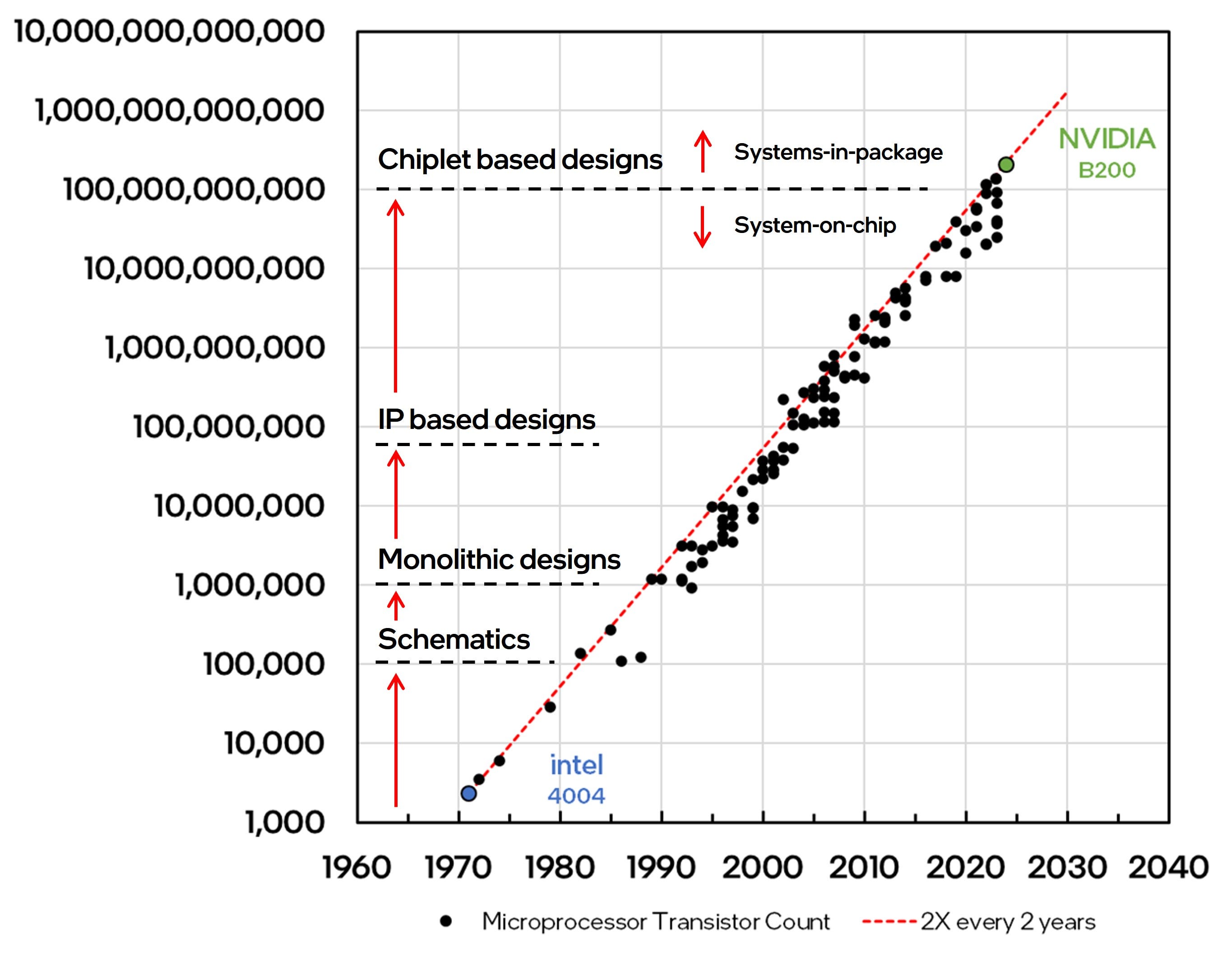
Since the late 1990s, advances in Computer-Aided Design (CAD) and Electronic Design Automation (EDA) have made circuit design more accessible, leading to the emergence of independent, third-party IP designers. These designers focus on creating standalone IP blocks that are fully tested and verified. Chip design companies can then integrate these IP blocks to create an array of complex SoC designs. Over time, this evolution led to a robust ecosystem of IP companies offering a wide range of digital logic, analog, and mixed-signal IPs, from foundational IPs like memory and logic standard cell libraries to specialized IPs such as high-speed analog I/O. Today, chips architects can rapidly put together complex SoCs with mostly off-the-shelf IPs, which are readily available and validated across most mainstream foundry process technologies.
In the near future, we can anticipate comparable advances within the emerging chiplet ecosystem. These advances will facilitate the rapid design and construction of custom chiplet IPs to exact specifications. System architects will be able to rapidly integrate multiple, fully validated chiplet designs into significantly larger systems within a package, while optimizing system-level performance and power efficiency and minimizing both unit cost and time-to-market.
Why Chiplets?
Two primary imperatives are driving the transition to disaggregated architectures and the use of discrete chips (or chiplets) within a single package using advanced wafer-level packaging technologies.
Functional imperative: A growing class of applications, primarily those serving high-performance computing workloads (e.g. datacenter server processors and machine learning accelerators) have scaled up in size to a point where they need more transistors than can fit on a single monolithic printed chip (i.e. a chip that is at or near the reticle limit imposed by lithography tools, ~800mm2). Recent examples are Intel Xeon and AMD EPYC server CPU processors and NVIDIA datacenter GPU processors (e.g. Blackwell). Regardless of other technological limitations, the sheer need for more transistors (typically > 100 billion) can only be met by increasing the total silicon footprint beyond a single reticle, which necessitates combining multiple chips within a single package, either side-by-side (2D or 2.5D) or stacked atop each other (3D).
Economic imperative: For a large class of computing and communication applications, chiplets enable architects and designers to overcome technological barriers (e.g. lower chip yields for large chips) or to improve unit economics (e.g. manage rising wafer prices of advanced nodes) or to improve time-to-market (e.g. by enabling re-use across product generations). In these applications, disaggregation of a large chip into multiple chiplets is more a choice and not so much a functional necessity. Recent examples include client CPU processors from Intel (e.g. Meteor Lake).

Regardless of the imperatives (functional or economic), a few common bottlenecks must be addressed to enable optimal system level performance when using disaggregation and chiplets. These bottlenecks will be critical to resolve in order for the chiplet ecosystem to develop – much akin to how the IP ecosystem developed a couple decades earlier.
Enabling Chiplets for All
Large incumbent chip companies have the scale and resources to independently develop and deploy complex new heterogeneous architectures with minimal support from the larger semiconductor ecosystem. Several such systems are already in production as mentioned earlier.
However, smaller and new chip companies, especially those designing systems for performance and bandwidth hungry workloads are likely to need help from the larger ecosystem to deploy such complex, disaggregated chiplet based architectures.
It should be noted that early generations of disaggregated architectures are just starting points and likely to keep evolving until system optimization is better understood – learning from these initial deployments will help improve system level understanding and drive the development of tools and techniques to further improve system level performance. In addition, advances in packaging technology (e.g. bump pitch scaling, direct Copper-to-Copper bonding and multi-level stacking) will continue to enable additional bandwidth at lower latencies, providing further room for system level performance enhancement.
The partitioning of a monolithic chip into multiple discrete chiplets needs to account for optimal placement of cutlines across the chip, for holistic design of memory hierarchy within a single chiplet and across multiple chiplets and for holistic design of intra- and inter-chip connectivity. Only then will system-level performance be able to match or exceed that of monolithic floorplans.
A variety of tools and techniques will be necessary in order to truly democratize chiplet design and enable it for the broader ecosystem:
Reference design platforms: EDA tools that assist in evaluating partitions of monolithic designs across various cut lines to determine best return on power and performance. Major EDA providers are already developing such capabilities.
Software-defined architecture: Given the ever-increasing complexity of large silicon systems, any exploration of multi-chip architectures can no longer rely on custom manual experiments. Such studies must be software and algorithm driven in a way that helps architects explore wider design and process spaces and simultaneously optimize multiple variables to guarantee system level performance.
Holistic cache hierarchy: Partitioning total available cache across a complex system while maintaining intra-die and die-to-die level coherency is a critical requirement, especially for high performance, memory hungry computing systems. Defining a holistic, coherent cache architecture is a major pre-requisite of complex multi-chiplet architectures.
Unified fabric architecture: Energy-efficient data movement across various components is a critical requirement for complex multi-chip systems. System architects need to be able to customize data movement in a way that enables coherency and scalability across a wide range of workloads and applications. Ideally, fabric architectures must also be agnostic to networking and connectivity protocols to facilitate mix-and-match in an open ecosystem.
Correct by construction: Just as the third-party design IP ecosystem evolved to offer fully validated and verified IP, guaranteed to perform to specification on a variety of mainstream foundry process nodes, so too will a new ecosystem need to evolve to offer fully validated chiplet IP, correct by construction so that system architects can integrate and deploy it into their systems with a high degree of confidence on the final system level performance and yield.
Software compatibility: Ensuring compatibility with legacy software programming models is a key requirement, especially for well-established processor systems that are migrating from monolithic to disaggregated architectures.
Open standards for chiplet connectivity: Open standards like Universal Chiplet Interconnect Express (UCIe) are necessary to make it easy to mix and match chiplets. UCIe offers high-bandwidth, low-latency, power-efficient, and cost-effective on-package connectivity between chiplets from different fabs using a range of packaging technologies.
Power delivery: EDA tools to optimize power delivery solutions across chiplets.
Fabric and Cache Architectures
In modern SoC architectures, interconnect fabrics play a crucial role in facilitating efficient communication between various on-chip components. These sophisticated networks serve as the nervous system of the SoC, enabling seamless data transfer among processors, memory units, peripherals, and other functional blocks, while maintaining coherency and optimizing performance and power. Similarly, on-chip caches play a vital role in modern SoC architectures, serving as compact, high-speed memory units strategically positioned between processors and main memory.
With increasing transistor density and chip complexity, the design and implementation of caches and interconnect fabrics have become critical factors in determining the efficiency and capabilities of modern SoCs across a wide range of applications, from mobile devices to high-performance computing systems. As seen in the figure below, bandwidth scaling has not kept up with compute scaling over several decades and memory and interconnect bandwidth is now the leading bottleneck to increase system performance. The interaction between caches and interconnect fabrics will become even more vital in improving bandwidth and reducing latency between compute and memory in highly complex, multi-chiplet disaggregated SiP architectures.
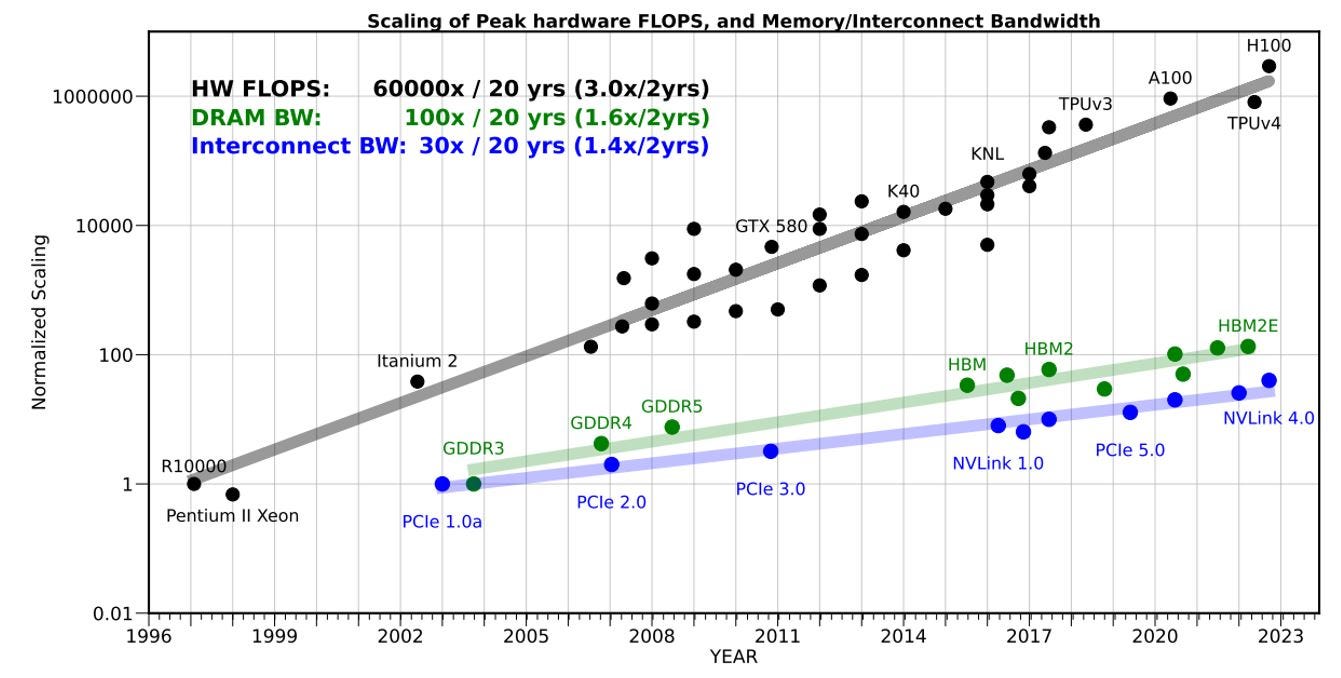
Over the past decade, fabric and cache architectures have evolved to accommodate the needs of large, monolithic SoC designs. So far, early chiplet-based disaggregated SiP designs have relied heavily on these legacy monolithic SoC frameworks. However, to fully harness the potential of future chiplet-based systems, a fundamental redesign of fabric and cache architectures is crucial. The traditional flat architectures of the SoC era must give way to multi-level compatible, hierarchical architectures – including hierarchical namespace, hierarchical routing, hierarchical networks, as well as hierarchical caching and coherency that can scale effectively across diverse disaggregated systems.
Just as CAD/EDA tools raised the abstraction in circuit design and simplified chip architecture during the SoC era, new software tools that facilitate multi-variable architectural explorations to determine optimal fabric and cache partitioning will prove to be crucial in the SiP era.
Baya Systems
Baya Systems is a new company that launched in June 2024 and aims to develop a software-defined approach to help architects build caches and fabrics that meet the needs of complex multi-chiplet designs.
Baya Systems is developing software that facilitates exploration across a range of chiplet architectures and tuned for a variety of representative workloads. These tools can allow architects to optimally design and partition system cache within and across chiplet boundaries while also providing for highly scalable custom fabric IP that is compatible with a host of industry standard protocols. Baya also aims to be the first to offer IP with multi-level cache coherency, solving a critical performance bottleneck for complex multi-die systems.
The views expressed herein are the authors’ own.
Moore in 1965 was surrounded by multichip packages, he did not need to imagine that. The MOS scaling law (Dennard) would not become the dominant factor until around 1980, since it needed CMOS to really work. NMOS, bipolar, and others disappeared because they did not scale.
Moore's law was an economic law - it says so in his own words. He just looked at it as the overall result of multiple innovations. There was no one dominant scaling effect back when he wrote it.
Intel's former CEO envisioned the chiplet as a strategy to counter TSMC's success in migrating to the next process node. Unfortunately, it did not pay off. I wonder why SiP has failed to be a better alternative to large monolithic chips or SoCs.